1 Helixmind Dashboard
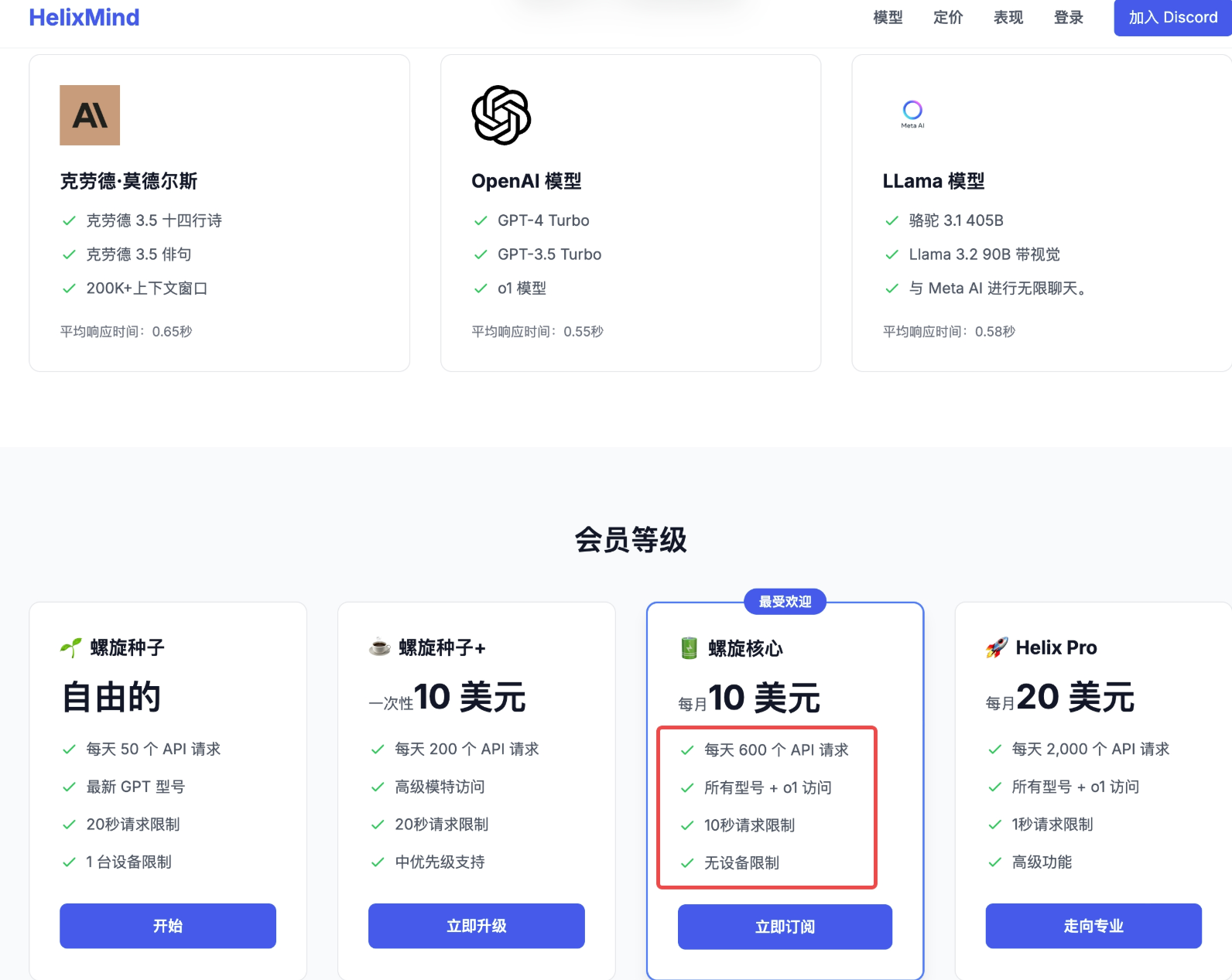 一个价格较低的AI聚合平台,类似openrouter,可使用网址为Helixmind,并自动帮你创建实例,部署openweb-ui
一个价格较低的AI聚合平台,类似openrouter,可使用网址为Helixmind,并自动帮你创建实例,部署openweb-ui
2 一个写prompt的技巧
1,使用AIStudio 或 Gemini app
2,创建一个新的Chat,选用G2.5P
3,开头的内容是“帮我写个prompt。我希望xxx。要求是yyy”
4,将生成的prompt放入另一chat中执行,得到结果
5,将结果贴回原chat“这是处理结果,你觉得怎样?”,分析问题,补充信息,生成新prompt(也可以提出自己希望得到的结果里面还应该/不应该 包含什么)
6,重复4和5…
prompt这个东西,和模型也有一定的“相性”,即“契合度”。所以即使是同一个任务,使用不同的模型时,也最好要这样处理一次。你只需要做的就是告诉模型,你希望要的是怎么样的结果。一开始不用太详细(因为自己不一定厘清了细节),先说大方向,设计,生成,测试,补充信息,修改…一次次的迭代,接近目标
3 Pad.ws Beta 现在向所有人开放!
这是一个在你的浏览器中运行的开发环境,就像一个笔记应用。
一个无限画布运行 Ubuntu,你可以在上面编码、绘制想法、启动终端或 VS Code
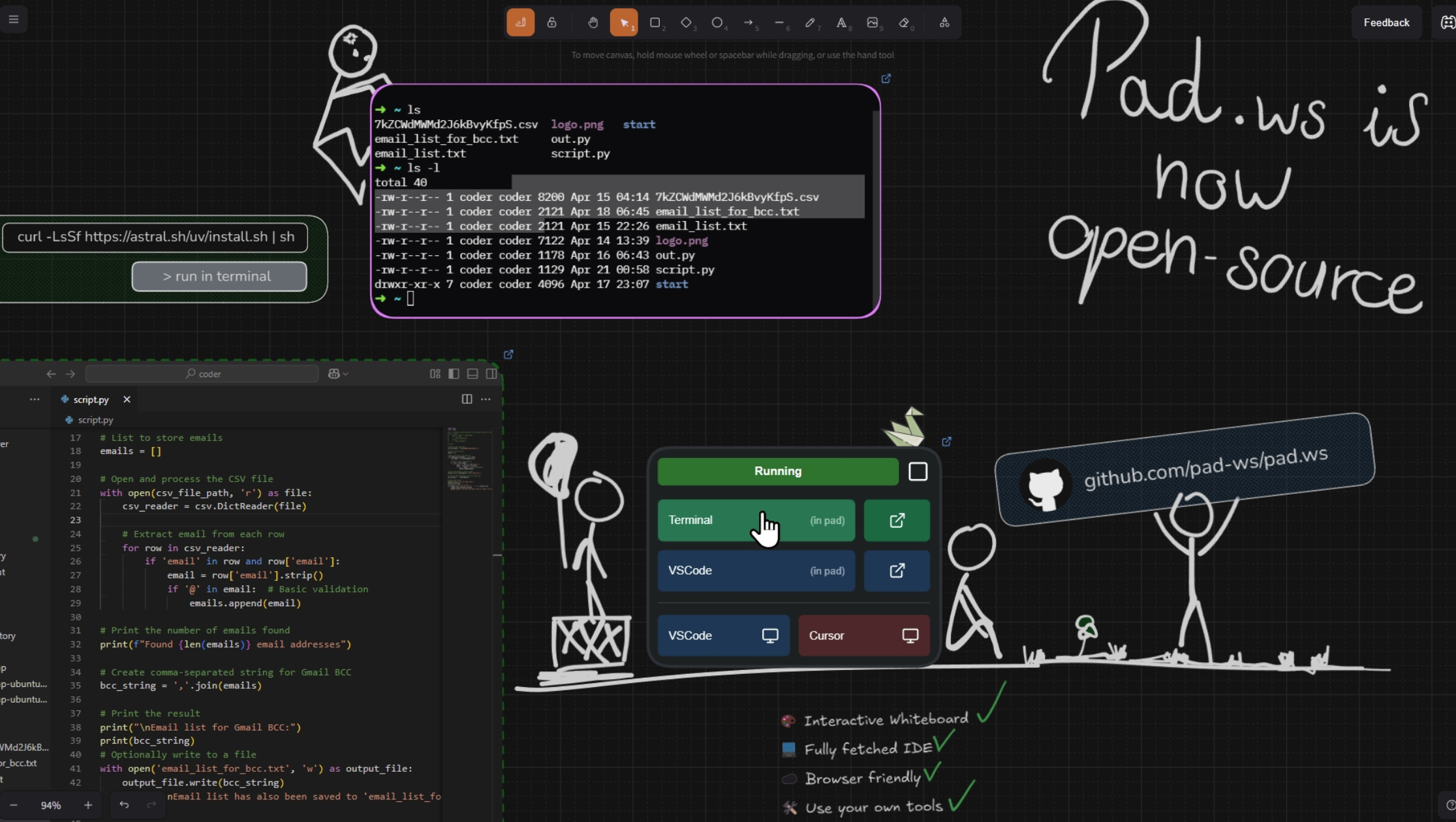
✨ 功能
- 🎨 交互式白板 - 使用 Excalidraw 绘制、素描和可视化您的想法
- 💻 功能完善的 IDE - 直接在白板上访问终端和 VS Code
- ☁️ 浏览器友好 - 从任何设备访问您的开发环境
- 🔄 无缝工作流 - 在视觉构思和编码之间切换
- 🛠️ 使用您自己的工具 - 从您的桌面客户端访问您的 VM(支持 VS Code & Cursor)
4 构造高效、高质量Al Prompt(提示词)的实用指南:七大黄金法则
如何构造高效、高质量 AI Prompt(提示词)的实用指南,适用于 ChatGPT 及其他生成式 AI 工具。
适用读者:想要在几分钟内上手并提升与 ChatGPT 或其他大型语言模型(LLM)互动质量的开发者、产品经理、内容创作者、数据分析师等。
核心理念:通过一套简单而系统的「七大黄金法则」,让模型更准确地理解你的意图、输出更符合预期的结果。
🧠 Prompt Engineering 是什么?
**Prompt Engineering(提示工程)**是为语言模型设计和优化提示语的过程,用于提高 AI 输出的准确性、相关性与创意性。它可应用于产品描述、故事创作、数据提取等多种任务。
-
关键思想:提示语越清晰明确,AI 输出越贴合预期
-
推荐结构:使用 {"your input here"} 作为可变输入位的占位符
-
鼓励探索不同的提示格式以发现更优效果
📏 黄金法则:编写 Prompt 七大黄金法则及示例
1️⃣ 将指令写在最前,并用 ### 或 """ 隔开上下文
说明:先告诉模型“要做什么”,再提供原始文本或背景,避免混淆。
错误示例 (Wrong Example)
-
EN: Rewrite the text below in more engaging language. {your input here}
-
CN: 将下面的文字改写得更生动。{你的文本}
正确示例 (Correct Example)
-
EN: Rewrite the text below in more engaging language. Text: """{your input here}"""
-
CN: 请将下文改写得更生动有趣。文本:"""{你的文本}"""
2️⃣ 具体且详细:交代目标、长度、格式、风格
说明:指明“写给谁、什么风格、多少字/段”,减少模型猜测。
错误示例
-
EN: Write a short story for kids.
-
CN: 给小朋友写一个短故事。
正确示例
-
EN: Write a funny soccer story for kids (≈100 words) that teaches perseverance is key to success, in the style of J. K. Rowling.
-
CN: 以 J.K. 罗琳的风格,用约 100 词写一个有趣的足球故事,向孩子们传递“坚持就是成功”的主题。
3️⃣ 直接给出“期望输出格式”样例
说明:先展示你想要的字段、排版或 JSON 结构,模型就会照着输出。
错误示例
-
EN: Extract house pricing data from the following text: {text}
-
CN: 从下文提取房价数据:{文本}
正确示例
-
EN: Desired format → House 1 | $1,000,000 | 100 sqm ; House 2 | $500,000 | 90 sqm. Now extract in that exact format from: """{text}"""
-
CN: 目标格式 → House 1 | $1,000,000 | 100 ㎡;House 2 | $500,000 | 90 ㎡。请根据该格式,从下文抽取:"""{文本}"""
4️⃣ 先零样本试试,不行再加少量示例
说明:很多任务 Zero-Shot 就足够;若效果差,再追加 1–3 条示范(Few-Shot)。
错误示例
-
EN: (Jumping straight to multiple examples without trying zero-shot.)
-
CN: (未尝试零样本就塞入一堆示例。)
正确示例
-
EN: Step 1 Zero-Shot – Extract brand names. Text: {text}. If inaccurate, Step 2 Few-Shot – “Text 1: Fintxer and YouTube… ⇒ Brand names: Fintxer, YouTube” …
-
CN: 步骤 1 零样本 – 提取品牌名。文本:{文本}。 若不准,步骤 2 少量示例 – “文本 1:Fintxer 和 YouTube… ⇒ 品牌名:Fintxer, YouTube” …
5️⃣ 示例仍无效?考虑微调(Fine-Tune)
说明:用高质量小数据集训练自定义模型,减少上下文长度、提高一致性。
错误示例
-
EN: Bloated prompt with dozens of inline examples on every request.
-
CN: 每次请求都塞几十条示例导致提示词膨胀。
正确示例
-
EN: Create a fine-tune set like {"prompt":, "completion":<ideal_output>} and train a lightweight model to save tokens and latency.
-
CN: 构建如 {"prompt":<输入>, "completion":<理想输出>} 的微调数据集,训练轻量模型以节省 Token 并降低延迟。
6️⃣ 精准表达,避免冗词
说明:越简洁、越聚焦,模型越容易命中要点。
错误示例
-
EN: ChatGPT, write a very long, complex, fancy sales page for my company selling sand in the desert…
-
CN: 亲爱的 ChatGPT,请为我在沙漠里卖沙子的公司写一篇超长、结构复杂、词藻华丽的销售文案……
正确示例
-
EN: Write five short sentences to sell desert sand.
-
CN: 用 5 句简洁文案推销沙漠里的沙子。
7️⃣ 用“引导词”暗示输出模式
说明:提示词中直接写出函数名、模块导入或章节标题,模型会模仿结构。
错误示例
-
EN: Write a Python function that plots my net worth over 10 years for different inputs on ROI.
-
CN: 写一个 Python 函数,针对不同 ROI 输入绘制 10 年净资产走势。
正确示例
-
EN: Python function (start with import matplotlib.pyplot as plt) that plots net worth over 10 years. Define def plot_net_worth(initial, roi): …
-
CN: Python 函数,请先写 import matplotlib.pyplot as plt,再定义 def plot_net_worth(initial, roi): … 用于绘制 10 年净资产曲线。
🔑 使用心得
-
结构顺序永远是「指令 →(可选)示例 → 上下文」。
-
如果输出不稳,先检查是否违反了前 3 条基本法则,再考虑 Few-Shot 或微调。
-
适当加入“若不确定请返回‘未知’”一类兜底指令,降低幻觉。
照此七法练习,你就能快速写出专业级 Prompt,显著提升 LLM 的听话程度与输出质量!
结语与实践建议
高质量 Prompt = 清晰的任务定义 + 示例 + 上下文 + 期望格式
实操步骤
- 拆解任务
-
目标:你希望模型产出什么?(摘要 / 表格 / 代码 / 营销文案)
-
受众:谁来阅读?需要怎样的语气和深度?
- 编写指令
-
把“目标+受众+限制”写在最前面
-
用 ### 或 """ 把背景文本包裹起来
- 预估输出格式
-
若结构化数据 → 提供列名、JSON 模板或 Markdown 表头
-
若自然语言 → 给 1–2 句「范例」或清晰的段落格式说明
- 测试与迭代
-
Zero-Shot:先不加示例,直接跑一次
-
Few-Shot:根据误差,加入 1–3 条最能代表多样性的示例
-
评估:检查准确率、冗余、风格一致性
- 高级优化
-
链式思考(Chain-of-Thought)提示:“一步一步思考并展示中间推理”
-
微调 / 适配器:对特定领域任务(例如医学文摘)建立小样本集,提高上下文窗口利用率
-
工具调用:结合代码执行、搜索、数据库查询等外部函数
常见坑 & 应对
小结
-
前三条法则确保“清晰指令 + 明确格式 + 充分上下文”
-
Rule 4–5处理“示例增补 → 微调”两档提升路径
-
Rule 6–7让输出更精准、风格更一致
-
遵循「先指令,再示例,最后上下文」的结构,几乎可以解决 80% 以上的输出偏差问题
按照本指南操作,你就能在数分钟内写出专业级 Prompt,让 LLM 成为高效得力的助手。祝你提示词愉快,产出爆表!
5 Google Search全面切换至Al Mode模式
Google搜索彻底迈入AI智能搜索
在 I/O 2025 上,Google 宣布其搜索体验将由传统的信息检索迈入“智能响应时代”。
通过整合 Gemini 2.5 模型,Google Search 正式推出更强大的 AI Mode,赋予搜索更深入的推理能力、实时互动、个性化分析与自动任务处理等多维度能力。
🧠更智能的问答体验
-
支持复杂、多轮、多模态提问;
-
响应中不仅有答案,还附带网页链接,帮助用户进一步探索;
-
通过 “query fan-out”机制,将问题自动拆解成多个子查询,深入搜索更广泛网页资源;
-
整合 Gemini 2.5 定制版本,提升理解力、回应准确性与逻辑结构。
🔬 深度功能拓展
🔹 Deep Search:自动生成专家级研究报告
-
针对复杂查询(如论文研究、技术主题),AI Mode 可发起上百次自动搜索;
-
汇总、推理并形成完整引用的深入报告,节省数小时调研时间;
-
适合高等教育、商业研究与学术探索场景。
📸 多模态与实时互动:搜索真正“看得见”
🔸 Search Live:摄像头实时视觉问答
-
集成 Project Astra 能力,用户可通过摄像头与 AI 互动;
-
支持“看到即问”:拍照某个装置、植物或街景,AI 实时反馈解释与链接;
-
可作为学习工具、旅行助理或故障识别助手使用。
🤖 智能代理(Agentic Capabilities):AI 为你办事
🔹 自动任务执行(Project Mariner)
-
示例:“帮我找两张本周六红人队比赛的低层看台门票”,AI 可自动查找、对比、分析并推荐结果;
-
当前支持:购票、订餐、预约,未来拓展更多场景;
-
与 Ticketmaster、StubHub、Resy 等平台合作,实现信息同步与结账转接。
🛍️ AI 购物助手
-
利用 Shopping Graph + Gemini 提供个性化产品筛选与购买建议;
-
支持 虚拟试穿功能:上传一张照片即可在数十亿服饰中模拟搭配效果;
-
可设置价格提醒与自动结账指令(需用户授权);
👤 个人化搜索体验
-
可选择连接 Gmail 等 Google 应用,允许 AI 在特定情境下使用个人上下文信息;
-
例如:搜索“本周末 Nashville 的音乐与美食活动”,AI 会结合用户的餐厅偏好、机票预订和住宿位置给出个性推荐;
-
所有信息使用过程用户自主可控,可随时开启/关闭个性数据接入。
📊 自定义图表与数据分析
-
AI Mode 可根据特定问题自动生成图表(例如:两支棒球队主场胜率对比);
-
支持体育、金融等领域的实时数据可视化。
AI Mode 已于美国全面上线,无需加入 Labs 实验;
新功能(如 Deep Search、Search Live、智能代理)将在未来几周分阶段上线,Labs 用户优先体验;
用户可在 Google App 或搜索页面切换至“AI Mode”标签使用。
官方介绍:https://blog.google/products/search/google-search-ai-mode-update/#ai-mode-search
6 Google推出可自主执行任务的编程智能体:
Jules云端运行能独立执行完整开发任务
在传统“代码助手”逐渐饱和的背景下,Google 正式推出;Jules ,定位为“一位真正能独立工作的虚拟编程搭档”,而非简单的代码自动补全工具。
Jules 不只是给你建议,而是独立执行完整开发任务,代表着“agentic development(代理式开发)”正式走出实验室,迈向实用化。
Jules 是什么?
Jules 是一个异步、自主的 AI 编程智能体,可接入你的真实代码仓库,在云端独立环境中运行以下任务:
-
自动生成测试用例
-
修复代码缺陷(bugs)
-
升级依赖版本(如 Node.js)
-
构建新功能模块
-
提供语音变更日志(audio changelog)
Jules 的六大关键特性
1. ✅ 真实代码库处理能力
-
区别于沙盒工具,Jules 可接入现有真实项目,读取全局上下文,跨文件/模块理解架构、依赖与逻辑结构;
-
能准确地对现有工程做出结构性调整,例如模块重构或版本迁移。
2. 🔄 并发任务执行(Parallel Execution)
-
所有任务在 Google Cloud VM 上运行;
-
支持并行执行多个请求,大幅加速多任务处理,适用于 CI/CD、重构等重负载流程。
3. 🔍 可视化工作流
-
执行前,Jules 会向开发者呈现其计划(计划逻辑 + 修改理由);
-
用户可先评估其操作动机,确保不会被“黑箱决策”影响代码质量。
4. 🔗 GitHub 无缝集成
-
Jules 内嵌于 GitHub 工作流中,无需单独平台登录或额外配置;
-
能直接针对 PR、commit、issue 等上下文触发 AI 助理操作。
5. 🎛️ 可控性强(User Steerability)
-
开发者可在前中后阶段自由调整 AI 的执行内容、方式或结果;
-
保证代码主导权始终掌握在人类手中,满足团队合规/审查等需求。
6. 🔊 语音摘要功能(Audio Summaries)
-
将代码提交历史转为语音 changelog;
-
适合项目回顾、团队同步、语音播报等多场景使用。
工作机制与核心能力
🧠 理解上下文、智能行动
-
克隆你的代码仓库到 Google Cloud 安全虚拟机(VM);
-
获取项目的完整上下文,而非基于单文件或 sandbox;
-
理解代码结构与意图,推理并执行更改。
🔁 异步运行
-
你不需要一直盯着它工作;
-
Jules 在后台并发执行任务,完毕后提供修改计划、理由与差异(diff)说明。
🔐 数据隐私保护
-
所有操作默认私有;
-
不会将私有代码用于模型训练;
-
数据完全隔离于 VM 内运行环境。
现已全球开放公测(Gemini 模型可用国家);
-
无需等待名单,免费试用(存在使用上限);
-
后续将引入付费机制;
-
访问:jules.google
7 Google全新AI UI设计工具亮相:Stitch一句
话生成完整UI和完整前端代码
在 Google I/O 2025 上,Google Labs 团队宣布推出新一代 UI 设计生成工具 Stitch,这是前身 Galileo AI 被 Google 收购后推出的升级版本。
Stitch 结合了 Google DeepMind 的最新模型(如 Gemini 和 Imagen),让开发者和设计师仅通过文本指令,即可生成、修改、翻译、导出完整的产品界面与前端代码。
-
✍️ 一句话生成完整 UI
-
🪄 Gemini + Imagen 赋能内容与视觉个性化
-
🌐 多语言本地化一键完成
-
💻 导出干净代码直接开发
-
🧩 深度融合 Gemini、Google Labs 生态
🎨 Stitch 能做什么?功能速览
1. 🔧 生成 UI 设计和产品界面(用一句话就行)
Stitch 是一款基于文本生成 UI 和产品页面的 AI 工具:
-
输入产品描述,即可自动生成符合设计规范的界面草图
-
支持快速调整排版、组件、配色方案
-
样式现代、结构可用,几乎无需二次修改
2. 🪄 调用 Gemini 和 Imagen 进行定制更新
👉 使用 Gemini:
-
修改 App 的主题风格(如从“商务蓝”变成“环保绿”)
-
自动生成适配不同语境/节日/用户类型的文案
📹 自动调整配色和内容
👉 使用 Imagen:
-
替换产品图片
-
根据语境生成适合的视觉素材
📹 自动切换语言和文案
- 要求 Gemini 自动将副本更新为不同的语言。
3. 💻 一键导出前端代码
在完成设计后,用户可以:
-
导出高质量、可部署的前端代码(HTML、CSS、React 等)
-
将设计直接嵌入开发流程中,无需“手工还原 UI”
Stitch 的前身是Galileo AI
-
Stitch 是从 Galileo AI 演化而来,后者是一款以“文字生成界面”为核心的初创产品
-
Galileo AI 已被 Google 正式收购
-
创始人 Arnaud Benard 加入 Google,与 Gemini 团队联合打造 Stitch
访问:https://stitch.withgoogle.com/
8 Google Al Studio 升级 :更快、更强、更智能
地构建Gemini应用集成Imagen、Veo、Lyria
等模型 支持Live API
Google 在 I/O 2025 上正式推出 Google AI Studio 的全新升级,面向开发者提供更强的 AI 原生开发平台。这次更新显著提升了 Gemini 模型的可用性、集成性与部署便捷性,打造“一站式 AI App 构建平台”。
核心更新亮点
1. 原生代码生成能力(Native Code Generation)
-
引入 Gemini 2.5 Pro 到 Studio 的代码编辑器,支持将文本/图像/视频提示直接生成 Web 应用;
-
新增 Build Tab:可快速构建、部署基于 AI 的 Web 应用(支持一键部署到 Cloud Run);
-
支持迭代开发:可在聊天对话中修改代码、查看 diff、返回历史版本。
2. 媒体生成中心(Generate Media)
-
集成 Imagen(图像)、Veo(视频)、Lyria(音乐) 与 Gemini(文本)多模态生成能力;
-
新增交互式音乐生成 App:PromptDJ,基于 Lyria RealTime 实现。
3.音频能力升级:语音更自然、响应更智能
🗣️ Gemini 2.5 Flash 支持的原生语音对话(Live API):
-
支持 30 多种自然人声(男女、口音、情感可调);
-
引入 主动音频识别能力:模型可区分用户说话与背景杂音,仅在适当时机应答;
-
更贴近人类自然对话节奏,适用于客服、虚拟助手、交互剧情等场景。
🔉 文本转语音(TTS)升级:
-
单人或多人对话生成;
-
支持语速、语调、情绪的多维控制;
Agentic 与工具生态
- 新增「Build」标签页
从文本、图像或视频 prompt 快速生成 Gemini 应用原型,集成 Gemini 2.5 Pro 模型。
- 智能代码助手
支持编辑现有应用代码,查看差异(diff)、回滚历史版本。
- 一键部署到 Cloud Run
无需配置服务器,自动托管 Gemini API Key,快速上线到生产环境。
- 全新「Generate Media」页面
集中调用 Imagen(图像)、Veo(视频)、语音生成等多模态模型。
- 支持 MCP(Model Context Protocol)
原生集成开源标准,方便构建复杂 AI 应用并对接第三方工具。
- URL Context 实验功能
模型可读取网页链接内容,用于摘要、比对、研究与查证。
🧱 1. 新增“Build”标签页:从 prompt 到 App 的极简生成
-
新的 Build 面板集成了 Gemini 2.5 Pro 模型
-
与 Google 的 GenAI SDK 紧密耦合
-
支持从文字、图像或视频 prompt 直接生成应用原型
-
自动生成 UI + 功能代码(适合前端或全栈原型搭建)
🛠️ 2. 代码助手功能上线:支持版本对比和撤回
-
可对已有项目进行 AI 辅助修改
-
提供“查看变更(diff)”能力
-
支持回退至历史版本(checkpoint 机制)
-
极大提升多人协作与版本控制效率
☁️ 3. 一键部署到 Cloud Run:零运维 AI App 生产化
-
应用构建完成后,可直接部署到 Google Cloud Run
-
Gemini API Key 会自动保存在服务端,提升安全性
-
便于开发者将原型迁移至线上环境投入使用
🖼️ 4. 新增“Generate Media”页面:整合所有多模态模型能力
-
集中访问和使用:
-
Imagen(图像生成)
-
Veo(视频生成)
-
Gemini(语言+跨模态生成)
-
Native speech 模型(语音生成)
-
一站式调用多模态生成模型,适配创意、教育、内容等应用场景
🧩 5. 支持 MCP(Model Context Protocol)标准:增强生态兼容性
-
Google GenAI SDK 现原生支持 MCP 协议
-
便于接入开源工具和第三方框架
-
为构建复杂对话系统或多模型交互应用提供标准接口
📸 示例截图展示:Colosseum 查询与代码并列视图
🌐 6. 实验功能:URL Context,让模型“读网页”
-
用户可直接输入网页链接
-
Gemini 可访问网页内容,用于:
-
事实核查(fact-checking)
-
内容摘要
-
信息对比
-
学术或企业级研究场景
详细内容:https://developers.googleblog.com/en/google-ai-studio-native-code-generation-agentic-tools-upgrade/